It’s obvious to everyone that we are currently going through a huge shift in the way that IT is used within our lives. The term “paradigm-shift” is much overused, but in this case it’s probably warranted. We all carry around a mobile device – perhaps more than one – and gradually our homes and cars are becoming digital arenas with our cars permanently connected to the carmaker and our homes even embedding devices that we can talk to and they can talk back. Even within the previously staid world of back-office IT, we are seeing the encroachment of mobile-first interfaces, deeper automation and API driven chatbots. All of these generate huge volumes of data that we are only just beginning to work out how to manage.
In truth most organisations still struggle to manage the comparatively low volumes of data generated by previous generations of IT – telcos struggle to analyse calls, banks struggle to work out their risk positions, and manufacturers drown in terabytes of test results. Even getting to an agreed financial position for statutory accounting or regulatory reporting is far from simple for many companies. However, companies born in the world of data (the likes of Google, Facebook, Ebay) all seem to deal with much larger volumes than older, more mature companies, so, how do they do that?
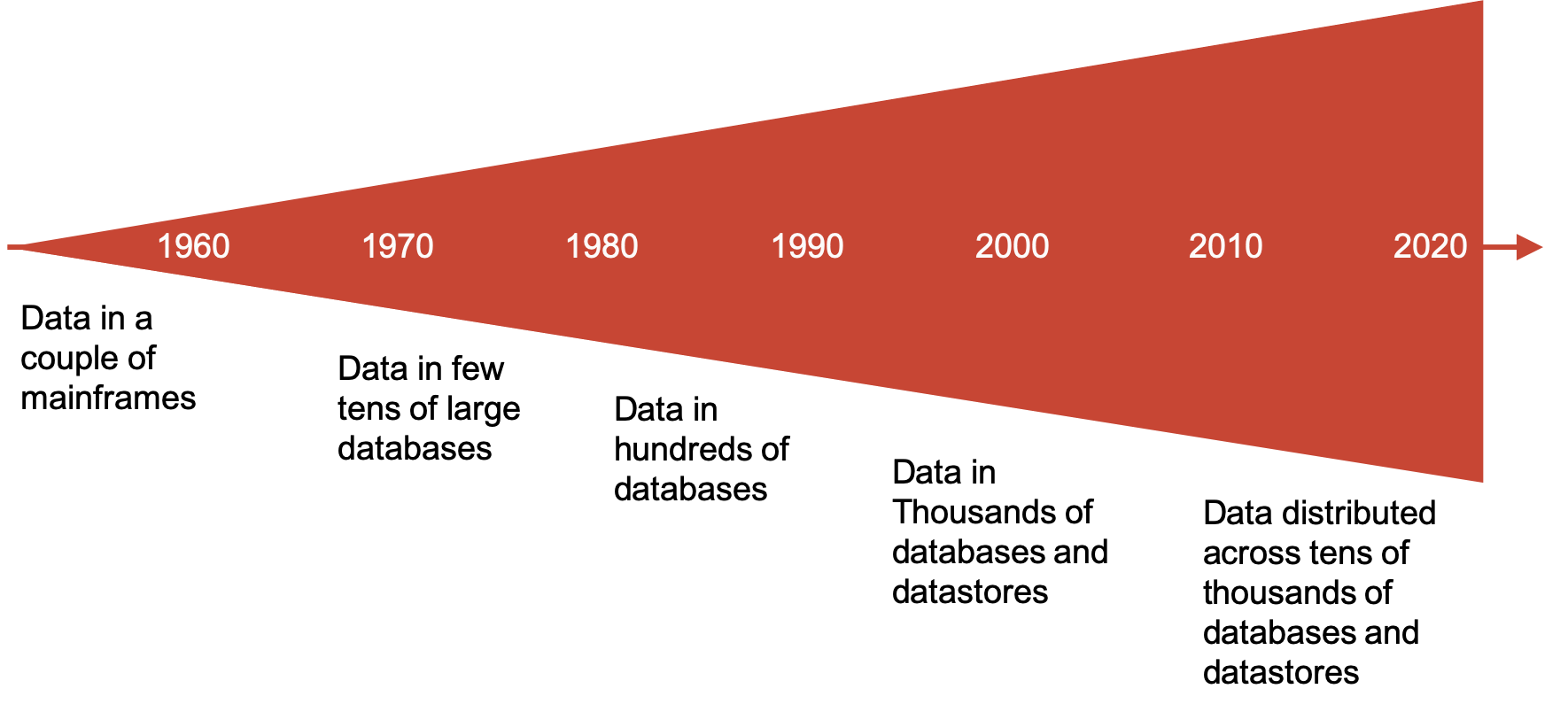
It’s not a technology problem and it won’t be solved by technical solutions – many of the technologies that those companies use have been open-sourced and are available to all, but most organisations that try to implement those technologies struggle to gain value and many “Bigdata” projects fail to meet their original goals and are often discarded.
The reality is that older organisations have a culture and an organisational structure that reflect and align to yesterdays IT models – organisations focus on systems and process rather than data. Almost every mature organisation will have an IT department where the ownership of systems is clear but not for data. On the business side, we frequently see “global process owners” and these structures are well funded and well respected, but we rarely see global data owners, let alone data owners with a budget. Many organisations have appointed a Chief Data Officer but in too many cases these are relatively junior roles, or are implemented alongside the existing organisation with minimal authority and responsibility.
The most recent “buzz” in IT is around Artificial Intelligence and Machine Learning. However, the fuel for those algorithms is raw data, and the quality of the output of those predictive engines is critically dependent on the quality of the inputs. Today, we are familiar with this concept as “Garbage-in, Garbage-out”, but some things don’t change and it was Charles Babbage in 1864 who first noted that you can’t get the correct answer from the wrong input data. For AI and ML to deliver value, we have to input data of an appropriate quality.
Where organisations have attempted to make a start and manage their data, it is often seen as just a “Data Governance” problem, other organisations see the solution as an implementation of “Data Science”, yet others as “Data Management”. The truth is that to become a data-driven organisation, it is all of these things and much more.
If mature organisations are to truly embrace the “data age”, then they must think much more deeply about how data is embedded into their organisations, and even to re-imagine their organisation as a data-first enterprise.
We, as enterprise architects, should be providing the thought leadership to our organisations to raise data strategy to be a top-level priority and so help our organisations become data-driven.

Leave a comment