Overview
The introduction of a discrete environment dedicated to data discovery and model building (e.g. a Datalab) can substantially deal with the lack of agility of more traditional data warehouses where agility has been deliberately locked out to deliver the resilience and reliability required by a mission-critical data warehouse. However, this does introduce a new challenge – i.e. how can we quickly and effectively promote the value discovered in the data discovery into the mission-critical execution environment of the data warehouse?
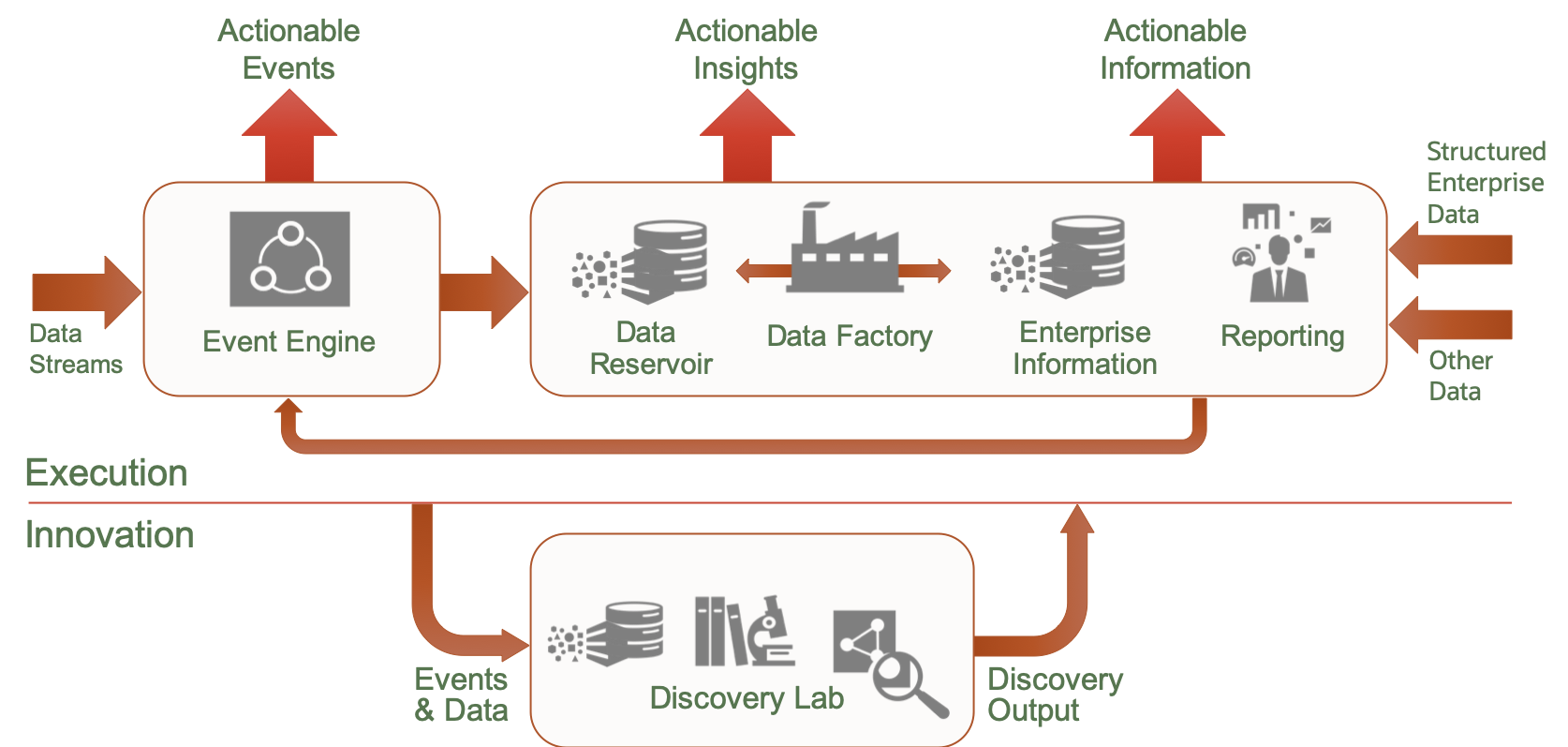
The value can typically have two aspects – the first being a algorithm (e.g. a transformation process, or a statistical, machine learning or artificial intelligence predictive model) and the second is a new data-set that is required in the execution environment.
It is clearly counter-productive to enforce a traditional ETL development process in this situation as this would throw away the agility gains of the discovery environment, so an accelerated implementation path is required. Given that the data discovery environment will have already dealt the early stages of a data development process (e.g. transformation mappings, data discovery, data quality assessment, algorithm definition, model build etc) then acceleration is clearly possible if those aspects can be re-used in the execution environment.
Capabilities
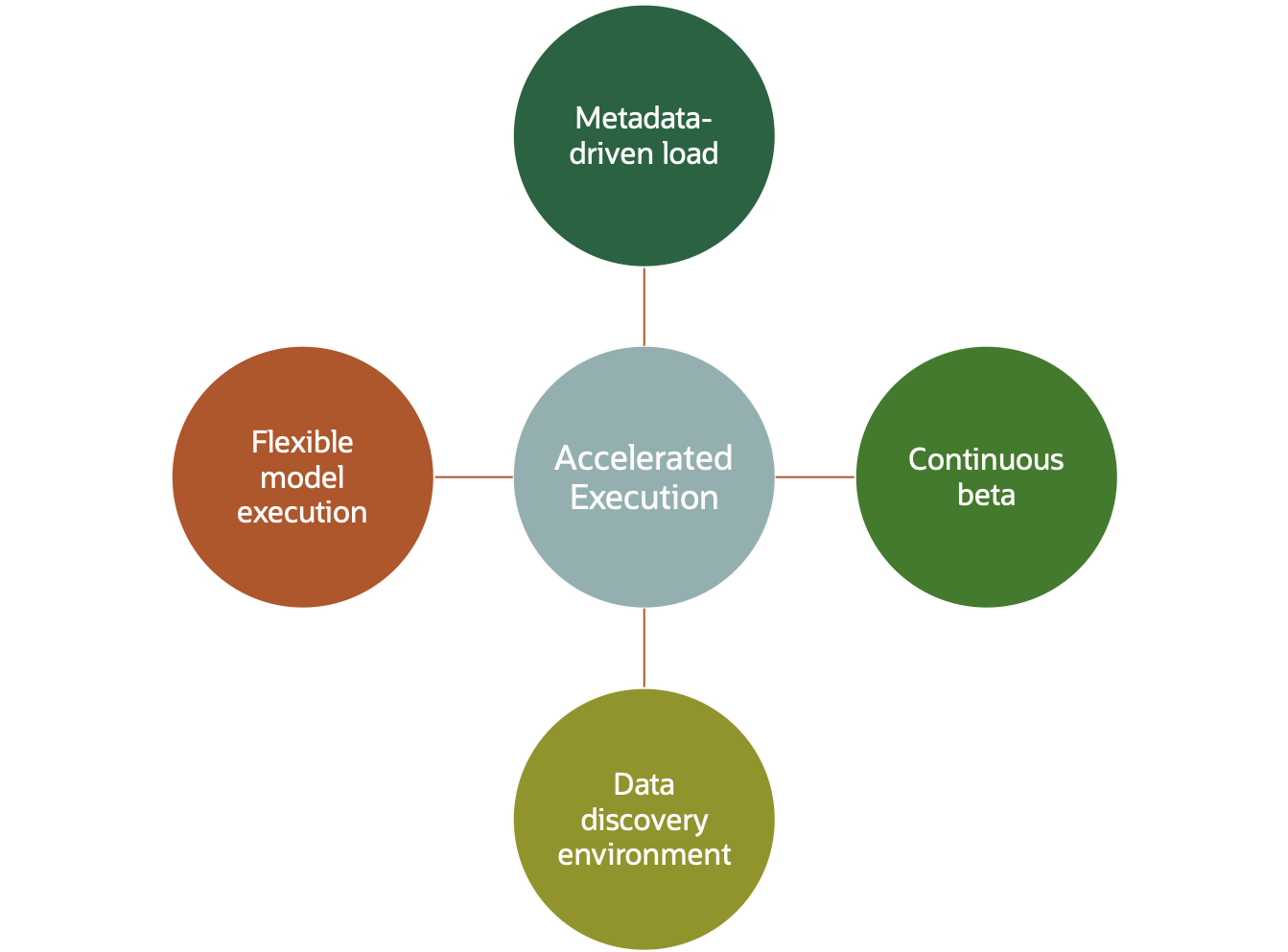
There are a number of execution environment capabilities that are essential to the accelerated implementation :
- A metadata-driven data load capability
The execution environment must be able to load data from a variety of sources and in a variety of formats without coding – i.e. configuration of the data load process must be sufficient for bringing in new data sources and changes to existing sources. Typical approaches to this may include code generators or highly abstracted ETL. At the most basic, the data ingest process must be able to automatically load data delivered in delimited format – and also populate the necessary metadata that described the new data to allows the new data to be accessed.
- A parallel ‘continuous-beta’ reporting capability
Given that there is added risk whenever implementation processes are accelerated, mitigation is needed to minimise failures. New data sets are not an issue here (assuming there is adequate protection against over-writing existing data sets) however, changed input data sets are a challenge. To manage these, it should be possible to support a shadow load environment where changed specification datasets can be loaded alongside the existing dataset format. These can be hidden or revealed for groups of users via metadata views. The query capabilities (i.e. the business model definition) must also be duplicated and made available to privileged user groups. Any existing unchanged data should not be replicated, but must still be visible as a ‘look-thru’ from the beta and data discovery environments.
- A flexible predictive model environment
Where the discoveries in the data discovery environment are algorithms or predictive models then a slightly different approach is required. In this case, it is likely that the best approach is to fully test the new model in the data discovery environment (the data discovery environment should have full access to production data) and then for the execution environment to be configured to allow the ‘drop-in’ of a new model alongside an existing model.
Typically the new model will be trialled with a subset of target customers in an A/B test, and so the model execution environment must offer the capability of run different models (or versions of models) on different customers. This is usually enabled by having a permanent trial/pilot capability implemented in the execution environment, with the model in that environment being the same as the live model when no trial is taking place.
Approach
In addition to these capabilities, a more flexible approach is also required to data acquisition in the short term. In many cases in the data discovery phase, new data would have been supplied on a ad-hoc basis. While the target for the final system may be, for example, daily feeds, to accelerate the inclusion of this new data a good approach is to schedule ad-hoc extracts at a lower frequency – e.g. daily or monthly. While this is not ideal, it often allows the new data to be made available months earlier while source systems are geared up to produce regular daily feeds. Typically these new data sources are delivered into the continuous beta environment described above.
Summary
It is important to design and build a separate data discovery environment with appropriate freedoms to allow for innovation, but also have access to real data. In the execution environment, it is essential that as much of the data acquisition and load processes are automated, together with support for both a “live” environment alongside a “continuous beta” to support A/B testing.

Leave a comment