What’s Next for Coders?
How AI coding tools may change the role of developers, shifting more value toward design, judgement, specification, and review.
In software development there has always been a tension between the effort invested before coding and the effort spent doing the coding. In mainframe days, the actual job of coding was extremely time-consuming — you had to wait overnight for a compilation, and a test run had to be planned days in advance.
The result was that a huge amount of effort went in before a single line of code was written. I’m old enough to remember Systems Analysts, Jackson Structured Programming, teams desk-checking code printed on green-lined “music paper” line by line, and near-book-length specifications typed by typists on paper. Fortunately, punched cards had been retired when I started — though not long before.
Then computing costs dropped at an incredible rate. Green screen dumb terminals were replaced by ever more powerful end-user devices, and today our laptops are surpassing the ever-shrinking commodity servers in data centres.
When the cost of compilation is near zero, software development became more trial-and-error than up-front design. Fast-fail and rework became the de facto standard in the various forms of agile software development. I’m not being disparaging about Scrum and similar approaches, but this is what they are at the core: write the code with limited up-front design, show the results, get feedback, and rework.
But there is a hidden truth here — agile works when you have great coders. Coders who instinctively understand the business requirement, the coding standards, good software design principles, and are able to make sound decisions based on experience and knowledge. This is hardest in large enterprises, where the knowledge required to produce code that integrates into a complex production environment exists nowhere but in the heads of senior developers.
Enter LLMs
Now enter LLMs to disrupt this model. Suddenly we don’t need coders — the LLMs are producing the code, so we no longer need them. Right?
Well, it’s true that we don’t need someone to type the actual code, but we still need those hard software decisions to be made. And even with expert coders, we still needed the fast-fail agile approach because even the experts found it hard to get it right first time.
The reality is that coders were doing the same job as the Systems Analysts and Software Architects of the mainframe era — making the critical decisions to produce a good software product — but those decisions were enshrined in code rather than in a detailed specification. Judgement was required, not just technical knowledge.
An LLM does not, at least in a basic configuration, have that background knowledge or the expertise to make those decisions. So we start building ever more complex memory structures — context layers that capture knowledge at different levels of abstraction, from project conventions down to individual preferences — that try to compensate. More on this below.
The quality ceiling
There’s a subtler limitation worth examining carefully. LLMs produce functionally competent but structurally fragile code. They can generate correct, idiomatic solutions to well-defined problems — but software is rarely a collection of well-defined isolated problems. The training data skews heavily towards small, standalone examples; there are few, if any, publicly available examples of complex enterprise-class integration, which is precisely where the real complexity lies. The result is code that works in isolation but struggles under the weight of real systems: it duplicates logic, misses architectural intent, and treats non-functional requirements — security, resilience, audit trails — as afterthoughts. These are exactly the dimensions that are most expensive to retrofit.
Vibe coding: great for prototypes, not for production
“Vibe coding” — the practice of driving an LLM with informal, iterative instructions rather than structured specifications — tries to work entirely on context combined with rapid iteration, and it is highly effective for demos and prototyping. The cost of producing a working prototype has never been lower.
But it produces code that is rarely maintainable and extremely difficult to integrate into a complex production environment. The non-functional requirements — security, resilience, scalability, audit — are almost never considered in vibe coding, yet they are frequently the hardest and most expensive to retrofit.
The feedback loop problem
One more thought about the fast-fail model: how do we know when to fail?
The best agile practice is to embed business users directly in the team — this is by far the most effective method, but it is resource-expensive. The right kind of end user is very often a critical person in the operational team who cannot be released from their day job.
So how does this dynamic change when an iteration drops from weeks to hours? If the iteration is a few hours rather than a few weeks, perhaps the expert end user can be available for this much shorter window. Shorter cycles may actually unlock the tight feedback loops that agile always aspired to but rarely achieved in practice.
Where does this leave us?
Some working conclusions:
- If LLMs are producing code, we need to encapsulate enterprise context and provide it to the LLM — through well-designed memory structures at multiple levels
- There is a level of expertise and judgement provided by expert coders that is difficult to replicate with a model trained primarily on general-purpose, publicly available code
- Iteration cycles can drop to hours or days rather than two weeks or more — which changes the economics of end-user involvement
- Expert end-user feedback is still required, but the time they need to contribute is vastly reduced
- Vibe coding can produce working models, but not production-quality code that can be reliably integrated into a production environment
A new model
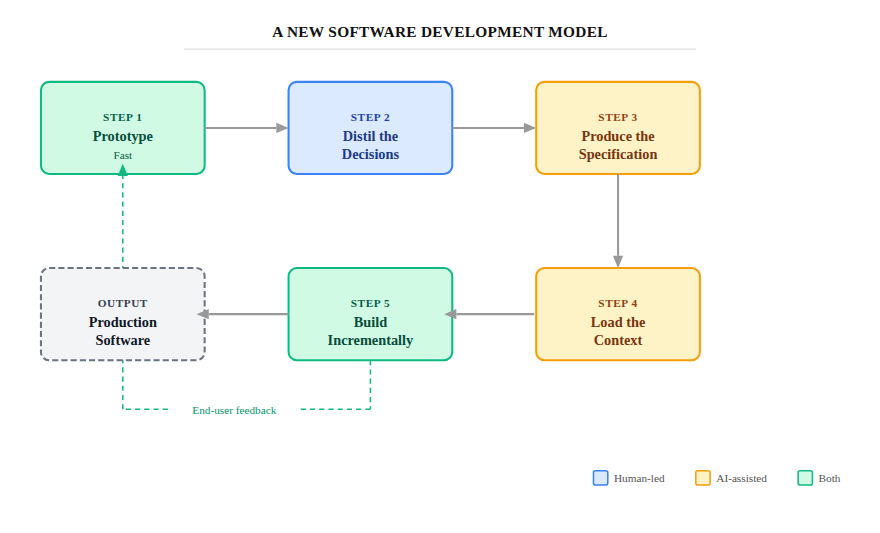
So what could a new development model look like? Here’s my suggestion:
1. Prototype fast
A short prototyping phase where working code is produced through vibe coding. Working interactively with end users and expert coders, workshop sessions iterate quickly, fail fast, and produce working models in just a few days. The goal here is shared understanding, not production code.
2. Distil the decisions
Expert coders work with the LLM to extract from the prototype the key specifications, design decisions, and constraints. This is the hardest step and the most important one: this is where non-functional requirements get surfaced, where integration constraints are identified, and where the judgement calls made informally during prototyping get written down explicitly.
3. Produce a proper specification
The expert coders — with LLM assistance — produce a detailed set of requirements, architectural designs, functional specifications, and test specifications. This is closer to the mainframe-era Systems Analyst’s work than anything in modern agile, but produced in a fraction of the time and with living documentation that feeds directly into the build.
4. Load the context
The full specification, together with enterprise context captured in structured memory layers, is provided to the LLM. The richer and better-organised this context, the better the LLM’s output.
5. Build incrementally
The expert coder works to build the product not in a big bang, but starting with scaffolding — incrementally adding functional slices until the product is complete. At each step, testing against the pre-defined tests and, where possible, demonstrating features to end users for early feedback.
This is quite different from today’s agile process. There is no agile team — just a single expert architect/designer/coder. Instead of writing code, this all-rounder works directly with end users, produces instructions (the spec) for the LLM and its agents, and makes the critical decisions that the LLM cannot. The build progresses quickly, but with frequent checkpoints and expert oversight at every stage.
So what should coders do next?
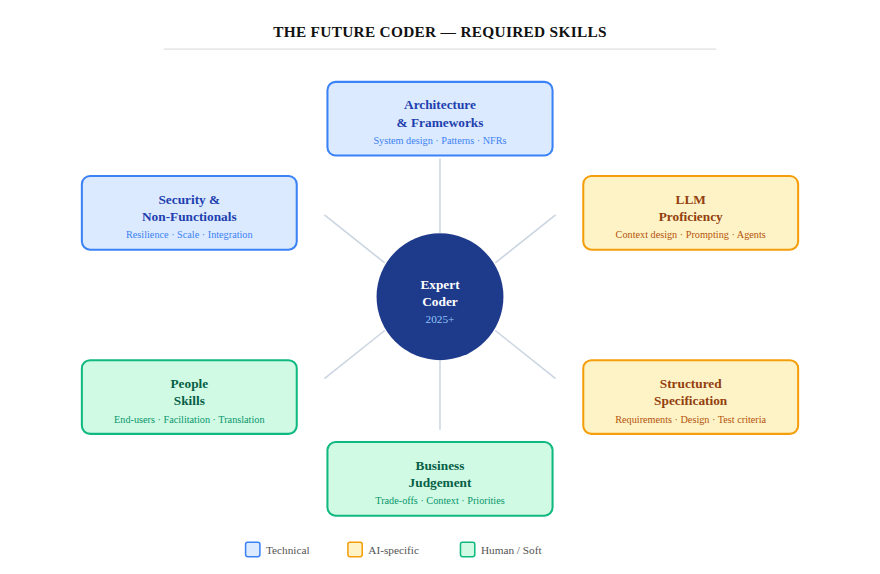
Good coders are already in short supply. My view is that they could become significantly more valuable over time — but only if they broaden their skills. Being good at writing code is simply not enough.
The skills that will matter:
- Architecture and frameworks — knowing how well-designed systems are structured, not just how to implement features
- People skills — working directly with end users, facilitating workshops, translating business needs into technical decisions
- Business judgement — making good calls about trade-offs, not just technically correct ones
- Non-functional requirements — scaling, enterprise integration, resilience, security; the things vibe coding ignores
- LLM proficiency — designing context memory structures, writing effective specifications, knowing the limits of what LLMs can and cannot judge
- Structured specification — the ability to capture requirements rigorously, in a form that an LLM (and a future engineer) can act on
We are entering an entirely new phase of software development — one that I believe is just as significant as the shift from punched cards to agile. The expert coder doesn’t disappear; they move up the stack, becoming the decision-maker, the specification author, and the quality guardian in a world where the actual typing is increasingly automated.
Exciting times indeed.